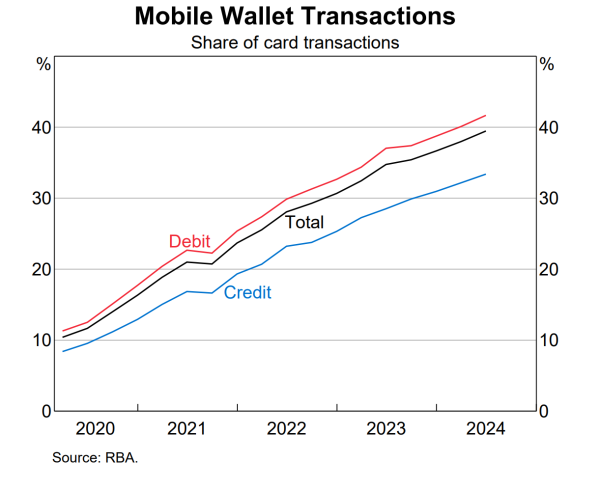
The Reserve Bank of Australia (RBA) recently released the 2024 Payments System Board Annual Report....
Some people think we’re ready to get psychological counselling from AIs. But in a tragedy...
I recently co-authored a white paper about verifiable credentials, with the founder and CEO of...
What do you think Large Language Models do? It’s easy to think LLMs think. Anthropomorphism...
George and I had a virtual blast recently on our podcast with David Birch. As...
Verifiable credentials are one of the most important elements of digital identity today. What exactly...
In the latest episode of our podcast Making Data Better, George Peabody and I are...
The term metadata has become rather loaded—perhaps even poisoned—for its association with telecommunications surveillance. But...
This week in the Boston Globe, Mike Orcutt writes about how old arguments over coding...
With Generative AI being used to imitate celebrities and creators, the question arises, is your...