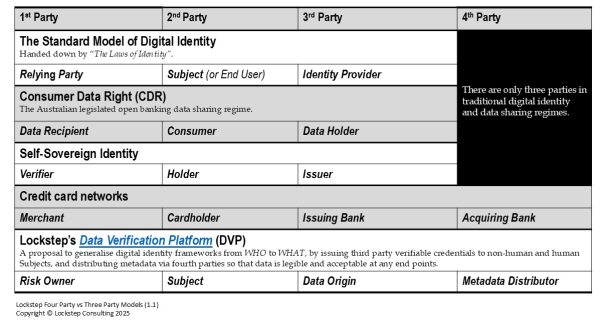
Image Copyright © Stephen Wilson, 2018. Here, in Part 3 of my Rethinking Digital Identity...
Image Copyright © Stephen Wilson, 2018. Continuing my rethink of digital identity, here are some...
Image credit: Sandro Halank, Wikimedia Commons, Creative Commons Licence BY-SA 4.0. Part 1 Digital identity...
If everybody knows that the captain lied, as Leonard Cohen sang, then whose problem is it?...
Infostructure patterns One of the hottest topics in the digital economy has for some time...
I was delighted and honoured to be invited by Professor Katina Michael to provide input...
Not that I’m a lawyer! But I’m giving a short speech on AI regulation at...
There’s been a recent rush of excitement on LinkedIn about the vividness of the latest...
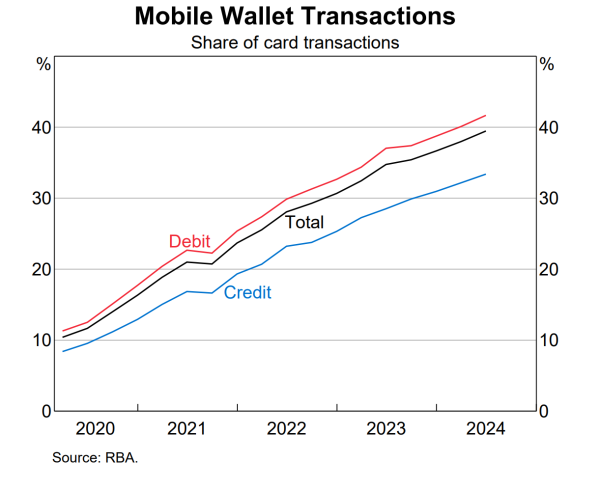
The Reserve Bank of Australia (RBA) recently released the 2024 Payments System Board Annual Report....
Some people think we’re ready to get psychological counselling from AIs. But in a tragedy...